
Non-ASCII characters: knowing them so to exploit them without errors on the site

They are an extension of the basic ASCII code, and to be precise a set of symbols that do not belong to the encoded standard, and thus include all special characters such as letters with accents, glyphs, ideograms and mathematical symbols. Non-ASCII coding is very broad, and non-ASCII characters can be as useful as they are “dangerous,” if not handled well: if we want to have a perfectly SEO-friendly site, therefore, it is good to approach this issue with the right awareness and to understand well what are the advantages of using non-ASCII characters, what are the risks, and what, above all, are the methods for detecting and solving possible problems.
What non-ASCII characters are and what they are used for
Unlike the standard ASCII encoding, which includes only alphanumeric characters and symbols such as the semicolon, non-ASCII characters are a much larger list of special characters that includes accented signs, glyphs, ideographs, Cyrillic letters, mathematical symbols, currency symbols and more. In computer science, therefore, the definition of a non-ASCII character is “a character that does not belong to the American Standard Code for Information Interchange (ASCII),” that is, the set of character codes that are normally used to represent letters, numbers and symbols.
Non-ASCII characters are used in many modern programming languages, such as HTML, XML and JavaScript, and are usually used by programmers to write source code or by developers as part of an encoding, but they can also be used in different ways. For example, they can be used to write documents that include words in other languages, to insert content that has been translated from another language, to create unique file names, and they are often leveraged in web graphics to make sites more appealing, to simplify data entry on the web page, or to add a personal touch to a Web site.
From a practical standpoint, non-ASCII characters can be entered manually or generated automatically by computer programs.To add this type of symbol to a document, it is necessary to use an application that supports Unicode encoding, which is the standard set of encodings that contain all non-ASCII characters. A possible alternative is to use HTML codes specially created for representing the full set of Unicode encoding.
Non-ASCII characters offer a number of advantages: first, they greatly increase flexibility in the creation of attractive Web sites and complex software development; second, they allow developers to create visually more attractive representations of the finished product image; and finally, they offer the possibility for end users to take advantage of the potential offered by this technology without having to master its complex technical rules.
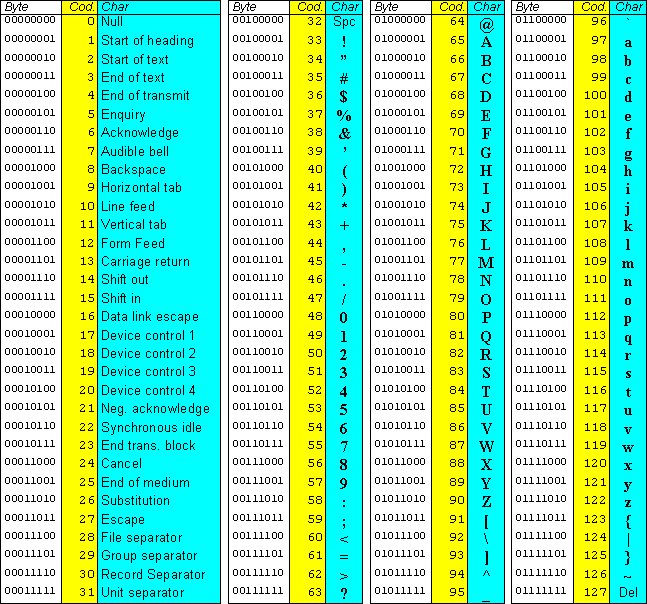
What is ASCII code, how it works and what it is used for
At this point, however, a digression on the ASCII Code, from the initials of American Standard Code for Information Interchange, which is “the” code of representation of alphanumeric characters and other symbols used in computer science that enables two machines to communicate with each other and transmit data, is unavoidable. Developed in 1963 and definitive since 1968, this 7-bit system is still widely used in modern communication systems and is based on a set of 128 binary combinations (128 decimal numbers ranging from 0 to 127) representing all standard characters, such as letters, numbers, symbols, and white spaces.
ASCII code was created to simplify computer writing and programming and can be used to store, organize, and transmit alphanumeric data; once sent, the text is decoded and displayed in a readable way on the screen; in addition, ASCII code can be used for user authentication in a computer network.
To be precise, ASCII code enables a computer to recognize and display alphanumerics, symbols, numbers, and punctuation marks. It consists of a table that assigns a set of numerical values to each character: for example, the number 65 corresponds to the capital letter A. In addition, the ASCII code can be separated into smaller groups, called character sets, which contain only those characters needed to write in a particular language or to create a specific user interface.
As mentioned, ASCII characters make represent the most common symbols used in writing and programming and are still used today as the de facto standard for most text documents. Each ASCII character is represented by a binary number, which can be represented in all languages.Returning to the previous example, the character “A” is represented by the binary code 01000001, meaning that the letter A occupies only 8 bits of memory in computer memory.
There are several types of ASCII characters, including uppercase letters, lowercase letters, numbers, and special symbols: each of them can be represented by a different binary code, and some letters have multiple variations depending on the language and spelling used. For example, in Italian the accented letter “e” can have two different variants depending on the type of accent, whether grave or acute, and thus becomes “è” or “é”.
ASCII characters are often used in web design and website development to create text templates that are easier to read or type on mobile devices; they can also be used in video and audio editing to highlight certain words or phrases in bold or italics, and some programs can use ASCII characters to create images or drawings in bitmap format.
Who invented the ASCII Code?
The ASCII Code was invented by Bob Bemer in 1963, so it is celebrating 60 years of life and career this year. Bemer was a computer engineer working for IBM who recognized the need for a universal system to represent alphanumeric characters in binary code.He therefore devised a 7-bit system, in the range of 0 to 127, identifying all alphanumeric characters, punctuation symbols, check marks and other graphic symbols, with the idea of making it easy to represent data on various devices and operating systems.
Considered a pioneer in the field of computer science, Bemer not only designed the ASCII Code, but also contributed to the definition of the standard format of email addresses and later also worked on the development of the FORTRAN programming language. In 1980, he was elected to the Hall of Fellows of the Institute of Electrical and Electronics Engineers (IEEE), and throughout his career he received numerous awards for his contributions to computer science.
His invention has had vast implications in the field of digital communication: the ASCII Code has fueled the development of computer technologies and is an essential element in most modern computer tools. Without this invention, it would have been impossible to represent non-ASCII characters such as Cyrillic or Japanese characters on computers, and it is thanks to Bob Bemer’s work that people today can easily exchange information digitally all over the world.
Not ASCII characters, practical functions
However, the ASCII code cannot handle all kinds of special characters, as are, for example, mathematical symbols, accented letters and other characters found in foreign languages, which is why codes such as Unicode and UTF-8 have been created, which are capable of precisely handling these kinds of features and thus expand the capabilities of the ASCII code, but which are “heavier” in terms of the disk space occupied.
This is why non-ASCII characters come in handy, which are as mentioned those that cannot be represented with the traditional 7-bit ASCII code: these are basically all the combinations ranging from 128 to 255 in the ASCII table, constituting the extended character set.
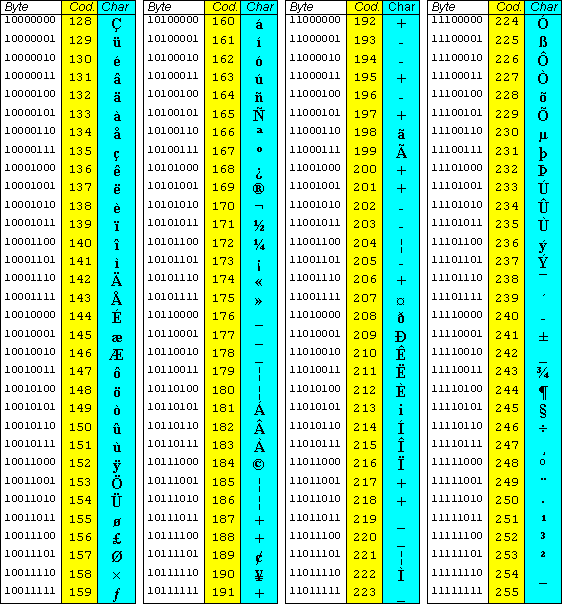
To represent these special characters, computer networks have introduced a new character set called Unicode that offers more than 65000 binary combinations to represent languages around the world, which are an extremely useful tool for programmers, designers and people writing text in multiple languages.
In addition to those described, another common application of non-ASCII characters is to create text with diverse fonts or decorations in print or web graphics; as such, designers can use non-ASCII characters to create particularly attractive headlines or special graphic effects such as Christmas-themed backgrounds or floral patterns solely with the help of the keyboard.

Non-ASCII characters can also be used to create more descriptive file names: for example, it may be easier to recognize a file called “Results_of_the_exam.pdf” than a file called “Results_of_the_exam123456789.pdf.” This makes it easier to find the desired file quickly without having to remember very long alphanumeric strings.
Still, non-ASCII characters can also be used for inserting emoji in instant messaging, which can help people better communicate their emotions and intentions without having to type long words or complex sentences.
How to type special characters
There are several ways to type special characters and insert them into a document of any kind, which rely on using a physical keyboard or a virtual keyboard.
If we have a physical keyboard, it may be necessary to press a number of keys at the same time, and for example in the Windows environment we can press ALT + the numerical code corresponding to the desired character (ALT+212 allows us to enter the È e capitalized with grave accent even in Office documents, to mention a common case).
In various programs or on the browser toolbar, then, it is possible to access the list of special characters by selecting a button that contains symbols such as the three suspension dots (…), and staying in the Office house we can look for the Special Characters option to find the desired characters.
Another simple method is to take advantage of the copy-paste option: that is, we just copy the character we need from a Web site or another document and paste it into our text.
Finally, mobile applications such as iOS and Android also offer the ability to type special characters with the device’s virtual keyboard.
Non-ASCII characters and sites: how to handle URLs and domain names
What happens if there are non-ASCII characters in a URL or domain name? Most modern browsers support the use of non-ASCII characters in a URL or domain name, as long as they are properly percentage-encoded. This means that non-ASCII characters must be encoded in a format called “URL encoding” before being inserted into the URL or domain name; after the URL or domain name has been encoded, it can be used like any other similar case.
However, there are some limitations to consider when using non-ASCII characters in a URL or domain name: for example, some browsers may not recognize non-ASCII characters and may display an error message instead of loading the corresponding Web page. In addition, because URL encoding is a complicated process, it can also lead to compatibility problems with some older browsers.
In addition, some domain registrars may not support non-ASCII characters in domain name registration; therefore, if we really want to use non-ASCII characters in a URL or domain name, we must first make sure that the domain registrar supports them before proceeding with registration.
How to handle non-ASCII characters: the risks and problems
In general, knowing how to properly handle non-ASCII characters can be very useful for all developers: in addition to making sure that content is accessible to a wider range of people, the proper use of non-ASCII characters can also help ensure that the code is stable and functions properly. By using the proper tools and paying attention to the way you write code, you can make sure that all non-ASCII characters are handled correctly, without problems or negative consequences for the site.
Many languages and alphabetic writing systems use non-ASCII (American Standard Code for Information Interchange) characters to represent special symbols or letters, and the need to support these characters is increasingly being felt in a variety of areas where content must be accessible to all. From a practical point of view, there are various cases in which we can resort to non-ASCII characters, starting with the use of accented letters or other special signs and ending with writing in languages that do not use the Latin alphabet, such as Chinese, Japanese, Cyrillic, or Arabic.
However, working with these characters can be complicated for developers because they are not always well handled by the source code. In particular, when working with digital text, non-ASCII characters can cause problems because some software tools may not be able to read special characters correctly, so it is necessary to know how to remove them so as to avoid problems. So, if we are working on documents with code that contains non-ASCII symbols, we need to pay attention to how the characters are handled: if the code is not written correctly, in fact, various problems can be encountered, such as decoding errors or displaying characters other than those expected.
There are a number of tools available that can help developers check their programs to make sure that all non-ASCII characters are handled correctly, and there are in particular many text editors that have specific options to allow users to set the editor’s encoding settings so that characters can be displayed correctly. In addition, some programming languages have built-in features that allow developers to control different forms of encoding, while other software allows non-ASCII characters to be handled, usually by parsing the characters and automatically converting them to their equivalent ASCII representation. Using these applications greatly simplifies character conversion and allows users to better manage documents containing these characters.
In some cases, it is possible to manually convert non-ASCII characters to ASCII codes, but it is a complicated process: to be successful with this technique, one must have a good knowledge of the encoding or languages from which the characters come. Writing programs such as Microsoft Word also offer support for handling non-ASCII characters through a feature called “substitute code,” which allows users to easily insert certain non-ASCII characters into the document: substitute code works by selecting the desired symbol or letter from the menu and then typing the corresponding code into the document.
Once the writing of the code is complete, it is common to perform a thorough check of strings containing the non-ASCII characters, taking advantage of the various online tools that can analyze the code and possibly discover encoding errors or other string handling problems. This can be especially useful when working with multilingual programs where special symbols and letters from different cultures and languages are present.
In conclusion, then, managing non-ASCII characters depends mainly on the type of document and the programs used to create or edit it: if we work on documents that contain such characters, it is important to remember that manual conversion can be a complicated and time-consuming process, and so the best solution might then be to use the applications available to simplify the management of the encoding of the entire document or individual words or phrases contained in it.
Non ASCII characters: how to identify problematic characters
And so, in order to avoid problems on the site it is first important to know how to recognize non-ASCII characters, and to do this we can look at the source code of our document: if we see numeric codes or strange symbols, then we are probably looking at a non-ASCII character.
Once we have identified non-ASCII characters, we can easily remove them with a text editor. Most popular text editors have an option that automatically searches for and replaces non-ASCII characters with something more readable. Another option is to manually copy and paste them into an editor that supports the UTF-8 format, a good idea especially if we are editing large amounts of material with many non-ASCII characters.
Although removing non-ASCII characters may seem complicated, the good news is that there is an easy way to prevent their appearance in our digital text: just make sure that the editor you use supports the standard UTF-8 Unicode encoding. This option should be available in most modern editors and is a great way to make sure there are no non-ASCII characters in our digital text.
Although non-ASCII characters can be a source of problems when working with digital text, knowing how to recognize and remove them can help us avoid problems: if we are using modern software, making sure that it supports standard UTF-8 Unicode encoding will allow us to write without problems, thus avoiding the appearance of non-ASCII characters.
How to remove a non-ASCII character
However, when, despite this check, we are faced with a problematic non-ASCII character, we can also decide to remove it from the text: first we will have to examine the text file and identify the character generating the difficulties, then proceed to removal, which can be done by different methods depending on the software used.
In Excel, it is possible to remove non-ASCII characters using the “Remove Characters” function within the “Tools” tab: we start by first selecting all the data in the worksheet and then click on the Tools tab at the top of the dialog box, then, we choose the Remove Characters function and select the type of character we want to remove.
In addition, word processing applications such as Microsoft Word also offer the option to remove non-ASCII characters quickly and easily. To use this option, simply select the text containing the non-ASCII characters and go to the Edit > Find and Replace menu. Then, we will enter the character symbol to be removed in the “Find” box and leave the “Replace with” box blank. Finally, press the “Replace All” button to remove all non-ASCII symbols from the document.
Another way to remove non-ASCII characters from a file is to use a text editor such as Notepad++ or Sublime Text – these applications offer a specific option in the Tools menu called Non-ASCII Removal that allows you to easily remove any non-ASCII symbols in the file.
