Comparison of Modeling Approaches for the Height–diameter Relationship: An Example with Planted Mongolian Pine (Pinus sylvestris var. mongolica) Trees in Northeast China


Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Area and Data Collection
2.2. Methods
2.2.1. Basic and Generalized Model
2.2.2. Basic and Generalized Mixed-Effects Models
2.2.3. Basic and Generalized Quantile Regression Models
2.2.4. Model Evaluation and Predictions with/without Calibration
3. Results
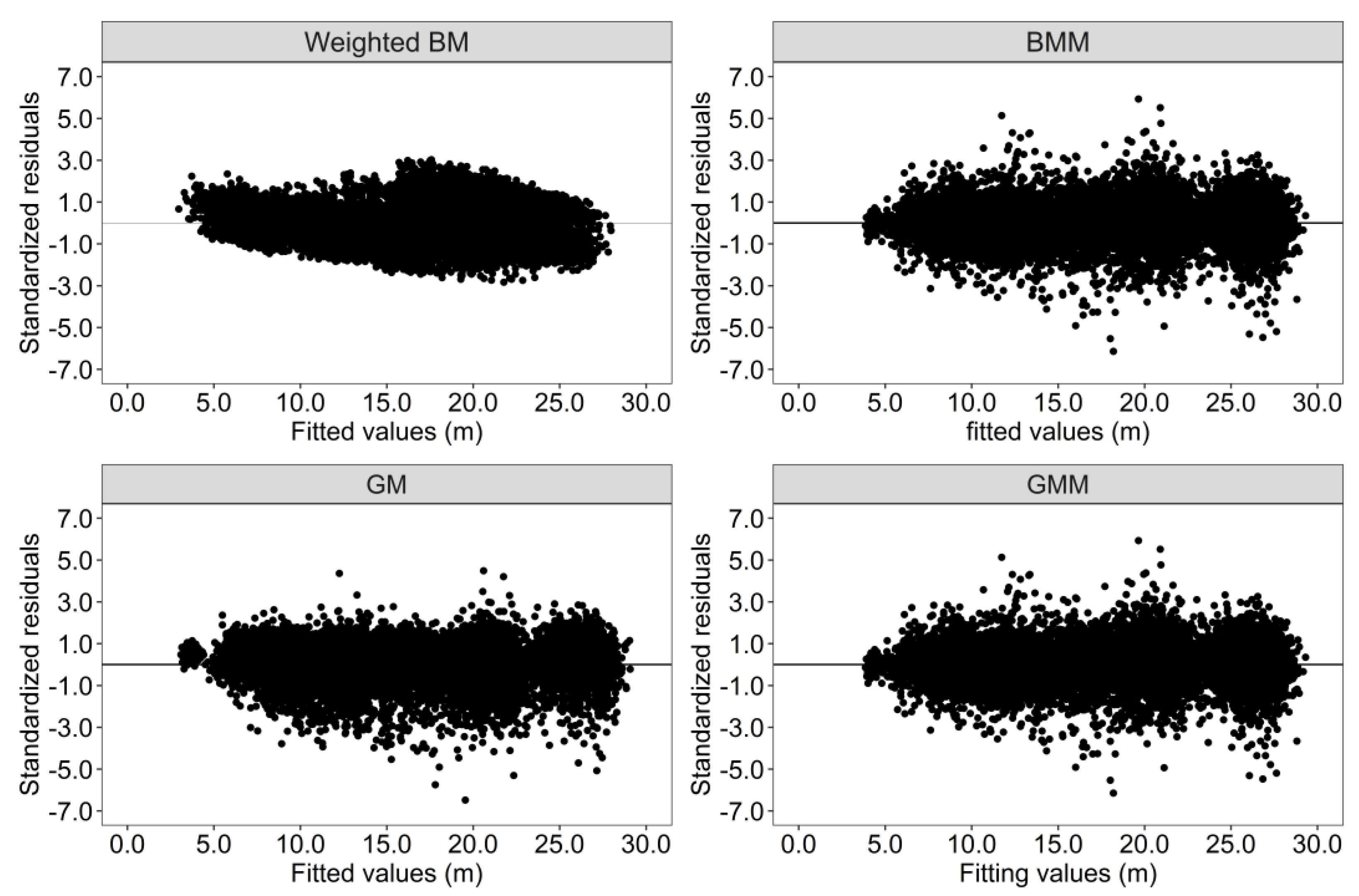
3.1. Model Fitting
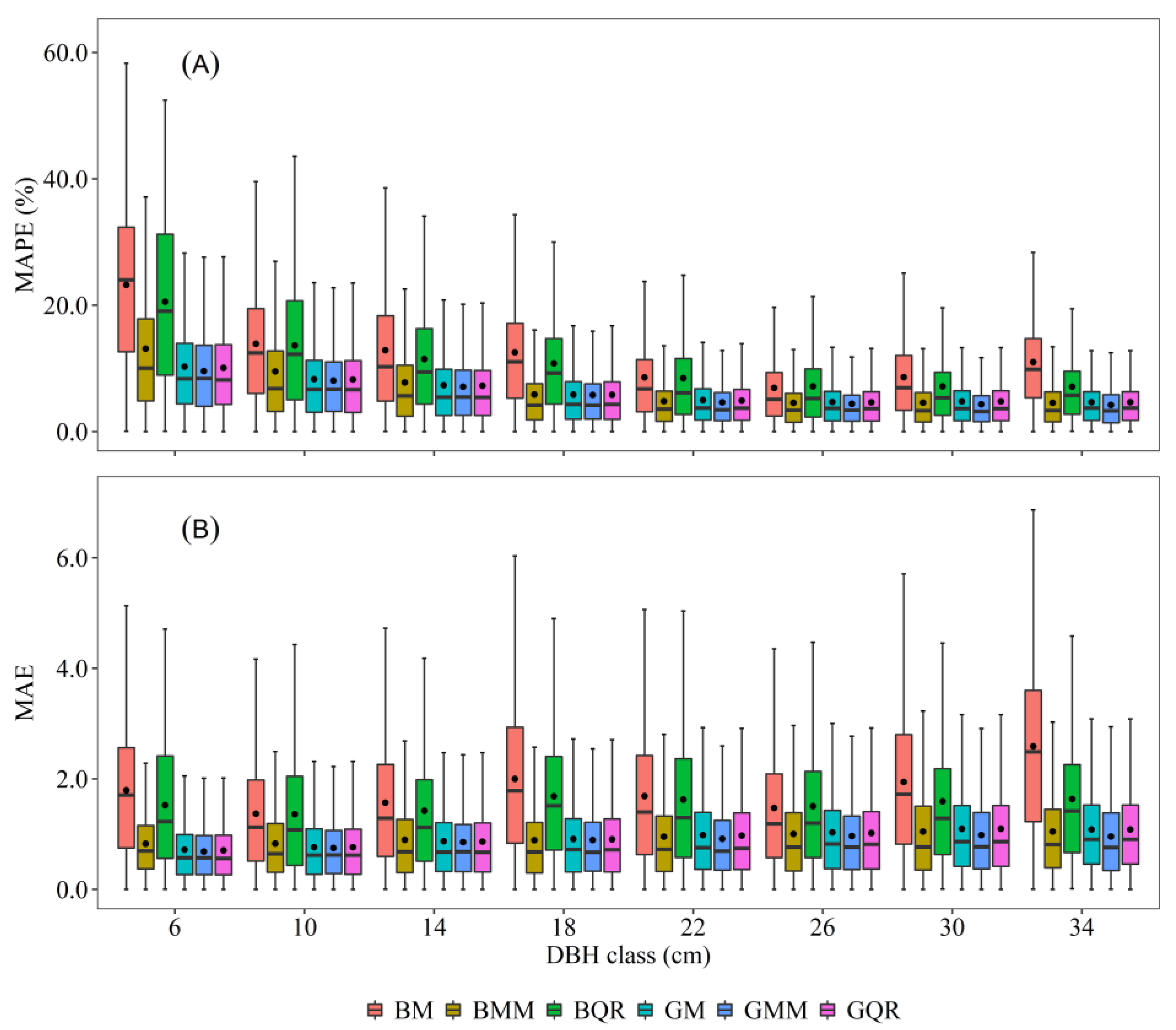
3.2. Model Evaluation and Prediction Comparison
4. Discussion
4.1. Specification of a Generalized H–D Model
4.2. Comparison of Modeling Approaches
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dong, L.; Zhang, Y.; Zhang, Z.; Xie, L.; Li, F. Comparison of tree biomass modeling approaches for larch (Larix olgensis Henry) trees in Northeast China. Forests 2020, 11, 202. [Google Scholar] [CrossRef] [Green Version]
- Trim, K.R.; Coble, D.W.; Weng, Y.; Stovall, J.P.; Hung, I.-K. A new site index model for intensively managed loblolly pine (Pinus taeda) plantations in the West Gulf Coastal Plain. For. Sci. 2020, 66, 2–13. [Google Scholar] [CrossRef] [Green Version]
- Yang, S.-I.; Burkhart, H.E. Evaluation of total tree height subsampling strategies for estimating volume in loblolly pine plantations. For. Ecol. Manag. 2020, 461, 117878. [Google Scholar] [CrossRef]
- Soares, P.; Tomé, M. Height–diameter equation for first rotation eucalypt plantations in Portugal. For. Ecol. Manag. 2002, 166, 99–109. [Google Scholar] [CrossRef]
- Mensah, S.; Pienaar, O.L.; Kunneke, A.; du Toit, B.; Seydack, A.; Uhl, E.; Pretzsch, H.; Seifert, T. Height—Diameter allometry in South Africa’s indigenous high forests: Assessing generic models performance and function forms. For. Ecol. Manag. 2018, 410, 1–11. [Google Scholar] [CrossRef]
- Raptis, D.I.; Kazana, V.; Kazaklis, A.; Stamatiou, C. Mixed-effects height–diameter models for black pine (Pinus nigra Arn.) forest management. Trees 2021, 35, 1167–1183. [Google Scholar] [CrossRef]
- Castaño-Santamaría, J.; Crecente-Campo, F.; Fernández-Martínez, J.L.; Barrio-Anta, M.; Obeso, J.R. Tree height prediction approaches for uneven-aged beech forests in northwestern Spain. For. Ecol. Manag. 2013, 307, 63–73. [Google Scholar] [CrossRef]
- Curtis, R.O. Height-diameter and height-diameter-age equations for second-growth Douglas-fir. For. Sci. 1967, 13, 365–375. [Google Scholar]
- Özçelik, R.; Cao, Q.V.; Trincado, G.; Göçer, N. Predicting tree height from tree diameter and dominant height using mixed-effects and quantile regression models for two species in Turkey. For. Ecol. Manag. 2018, 419, 240–248. [Google Scholar] [CrossRef]
- Xie, L.; Widagdo, F.R.A.; Miao, Z.; Dong, L.; Li, F. Evaluation of the mixed-effects model and quantile regression approaches for predicting tree height in larch (Larix olgensis) plantations in northeastern China. Can. J. For. Res. 2022, 52, 309–319. [Google Scholar] [CrossRef]
- Crecente-Campo, F.; Tomé, M.; Soares, P.; Diéguez-Aranda, U. A generalized nonlinear mixed-effects height–diameter model for Eucalyptus globulus L. in northwestern Spain. For. Ecol. Manag. 2010, 259, 943–952. [Google Scholar] [CrossRef] [Green Version]
- Castedo-Dorado, F.; Dieguez-Aranda, U.; Barrio-Anta, M.; Sanchez-Rodriguez, M.; von Gadow, K. A generalized height-diameter model including random components for radiata pine plantations in northwestern Spain. For. Ecol. Manag. 2006, 229, 202–213. [Google Scholar] [CrossRef]
- Saud, P.; Lynch, T.B.; KC, A.; Guldin, J.M. Using quadratic mean diameter and relative spacing index to enhance height–diameter and crown ratio models fitted to longitudinal data. Forestry 2016, 89, 215–229. [Google Scholar] [CrossRef] [Green Version]
- Ciceu, A.; Garcia-Duro, J.; Seceleanu, I.; Badea, O. A generalized nonlinear mixed-effects height–diameter model for Norway spruce in mixed-uneven aged stands. For. Ecol. Manag. 2020, 477, 118507. [Google Scholar] [CrossRef]
- Sharma, M.; Parton, J. Height–diameter equations for boreal tree species in Ontario using a mixed-effects modeling approach. For. Ecol. Manag. 2007, 249, 187–198. [Google Scholar] [CrossRef]
- Huang, S.; Wiens, D.P.; Yang, Y.; Meng, S.X.; Vanderschaaf, C.L. Assessing the impacts of species composition, top height and density on individual tree height prediction of quaking aspen in boreal mixedwoods. For. Ecol. Manag. 2009, 258, 1235–1247. [Google Scholar] [CrossRef]
- Sharma, R.P.; Vacek, Z.; Vacek, S.; Kučera, M. Modelling individual tree height–diameter relationships for multi-layered and multi-species forests in central Europe. Trees 2019, 33, 103–119. [Google Scholar] [CrossRef]
- Zang, H.; Lei, X.D.; Zeng, W.S. Height-diameter equations for larch plantations in northern and northeastern China: A comparison of the mixed-effects, quantile regression and generalized additive models. Forestry 2016, 89, 434–445. [Google Scholar] [CrossRef]
- Huang, S.; Titus, S.J.; Wiens, D.P. Comparison of nonlinear height–diameter functions for major Alberta tree species. Can. J. For. Res. 1992, 22, 1297–1304. [Google Scholar] [CrossRef]
- Ng’andwe, P.; Chungu, D.; Yambayamba, A.M.; Chilambwe, A. Modeling the height-diameter relationship of planted Pinus kesiya in Zambia. For. Ecol. Manag. 2019, 447, 1–11. [Google Scholar] [CrossRef]
- Gollob, C.; Ritter, T.; Vospernik, S.; Wassermann, C.; Nothdurft, A. A Flexible Height–Diameter Model for Tree Height Imputation on Forest Inventory Sample Plots Using Repeated Measures from the Past. Forests 2018, 9, 368. [Google Scholar] [CrossRef] [Green Version]
- Kearsley, E.; Moonen, P.C.; Hufkens, K.; Doetterl, S.; Lisingo, J.; Bosela, F.B.; Boeckx, P.; Beeckman, H.; Verbeeck, H. Model performance of tree height-diameter relationships in the central Congo Basin. Ann. For. Sci. 2017, 74, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Pinero, J.; Bates, D. Mixed-Effects Models in S and S-PLUS (Statistics and Computing); Springer: New York, NY, USA, 2000. [Google Scholar]
- Zhang, X.; Lei, Y.; Liu, X.J. Modeling stand mortality using Poisson mixture models with mixed-effects. iForest-Biogeosci. For. 2015, 8, 333. [Google Scholar] [CrossRef]
- Timilsina, N.; Staudhammer, C.L. Individual tree-based diameter growth model of slash pine in Florida using nonlinear mixed modeling. For. Sci. 2013, 59, 27–37. [Google Scholar] [CrossRef]
- Mehtätalo, L.; de-Miguel, S.; Gregoire, T.G. Modeling height-diameter curves for prediction. Can. J. For. Res. 2015, 45, 826–837. [Google Scholar] [CrossRef] [Green Version]
- Lappi, J. A longitudinal analysis of height/diameter curves. For. Sci. 1997, 43, 555–570. [Google Scholar]
- Temesgen, H.; Zhang, C.; Zhao, X. Modelling tree height–diameter relationships in multi-species and multi-layered forests: A large observational study from Northeast China. For. Ecol. Manag. 2014, 316, 78–89. [Google Scholar] [CrossRef]
- Calama, R.; Montero, G. Interregional nonlinear height-diameter model with random coefficients for stone pine in Spain. Can. J. For. Res. 2004, 34, 150–163. [Google Scholar] [CrossRef] [Green Version]
- Fang, Z.; Bailey, R. Height–diameter models for tropical forests on Hainan Island in southern China. For. Ecol. Manag. 1998, 110, 315–327. [Google Scholar] [CrossRef]
- Koenker, R.; Bassett, G., Jr. Regression quantiles. Econom. J. Econom. Soc. 1978, 46, 33–50. [Google Scholar] [CrossRef]
- Zhang, L.; Bi, H.; Gove, J.H.; Heath, L.S. A comparison of alternative methods for estimating the self-thinning boundary line. Can. J. For. Res. 2005, 35, 1507–1514. [Google Scholar] [CrossRef]
- Cao, Q.V.; Wang, J.J.F.S. Evaluation of methods for calibrating a tree taper equation. For. Sci. 2015, 61, 213–219. [Google Scholar] [CrossRef] [Green Version]
- He, P.; Hussain, A.; Shahzad, M.K.; Jiang, L.; Li, F. Evaluation of four regression techniques for stem taper modeling of Dahurian larch (Larix gmelinii) in Northeastern China. For. Ecol. Manag. 2021, 494, 119336. [Google Scholar] [CrossRef]
- Bohora, S.B.; Cao, Q.V. Prediction of tree diameter growth using quantile regression and mixed-effects models. For. Ecol. Manag. 2014, 319, 62–66. [Google Scholar] [CrossRef]
- Raptis, D.I.; Kazana, V.; Kechagioglou, S.; Kazaklis, A.; Stamatiou, C.; Papadopoulou, D.; Tsitsoni, T. Nonlinear Quantile Mixed-Effects Models for Prediction of the Maximum Crown Width of Fagus sylvatica L., Pinus nigra Arn. and Pinus brutia Ten. Forests 2022, 13, 499. [Google Scholar] [CrossRef]
- Sun, Y.; Gao, H.; Li, F. Using linear mixed-effects models with quantile regression to simulate the crown profile of planted Pinus sylvestris var. Mongolica trees. Forests 2017, 8, 446. [Google Scholar] [CrossRef] [Green Version]
- Miao, Z.; Widagdo, F.R.A.; Dong, L.; Li, F. Prediction of branch growth using quantile regression and mixed-effects models: An example with planted Larix olgensis Henry trees in Northeast China. For. Ecol. Manag. 2021, 496, 119407. [Google Scholar] [CrossRef]
- Wang, T.; Xie, L.; Miao, Z.; Widagdo, F.R.A.; Dong, L.; Li, F. Stand Volume Growth Modeling with Mixed-Effects Models and Quantile Regressions for Major Forest Types in the Eastern Daxing’an Mountains, Northeast China. Forests 2021, 12, 1111. [Google Scholar] [CrossRef]
- Temesgen, H.; Monleon, V.; Hann, D. Analysis and comparison of nonlinear tree height prediction strategies for Douglas-fir forests. Can. J. For. Res. 2008, 38, 553–565. [Google Scholar] [CrossRef] [Green Version]
- Mehtätalo, L.; Lappi, J. Biometry for Forestry and Environmental Data: With Examples in R; Chapman and Hall/CRC: Boca Raton, FL, USA, 2020. [Google Scholar]
- Fu, L.; Zhang, H.; Sharma, R.P.; Pang, L.; Wang, G. A generalized nonlinear mixed-effects height to crown base model for Mongolian oak in northeast China. For. Ecol. Manag. 2017, 384, 34–43. [Google Scholar] [CrossRef]
- Miao, Z.; Zhang, L.; Widagdo, F.R.A.; Dong, L.; Li, F. Modeling the number of the first-and second-order branches within the live tree crown of Korean larch plantations in Northeast China. Can. J. For. Res. 2021, 51, 704–719. [Google Scholar] [CrossRef]
- Zhu, J.; Zheng, X. The prospects of development of the Three-North Afforestation Program (TNAP): On the basis of the results of the 40-year construction general assessment of the TNAP. Chin. J. Ecol. 2019, 38, 1600–1610. [Google Scholar]
- Zheng, X.; Zhu, J.; Yan, Q.; Song, L. Effects of land use changes on the groundwater table and the decline of Pinus sylvestris var. mongolica plantations in southern Horqin Sandy Land, Northeast China. Agric. Water Manag. 2012, 109, 94–106. [Google Scholar] [CrossRef]
- Stankova, T.V.; Diéguez-Aranda, U. Height-diameter relationships for Scots pine plantations in Bulgaria: Optimal combination of model type and application. Ann. For. Res. 2012, 56, 149–163. [Google Scholar]
- Scolforo, H.F.; McTague, J.P.; Burkhart, H.; Roise, J.; Campoe, O.; Stape, J.L. Eucalyptus growth and yield system: Linking individual-tree and stand-level growth models in clonal Eucalypt plantations in Brazil. For. Ecol. Manag. 2019, 432, 1–16. [Google Scholar] [CrossRef]
- Han, Y.; Lei, Z.; Ciceu, A.; Zhou, Y.; Zhou, F.; Yu, D. Determining an Accurate and Cost-Effective Individual Height-Diameter Model for Mongolian Pine on Sandy Land. Forests 2021, 12, 1122. [Google Scholar] [CrossRef]
- Richards, F.J. A flexible growth function for empirical use. J. Exp. Bot. 1959, 10, 290–301. [Google Scholar] [CrossRef]
- Karatepe, Y.; Diamantopoulou, M.J.; Özçelik, R.; Sürücü, Z. Total tree height predictions via parametric and artificial neural network modeling approaches. iForest-Biogeosci. For. 2022, 15, 95. [Google Scholar] [CrossRef]
- Patrício, M.S.; Dias, C.R.; Nunes, L. Mixed-effects generalized height-diameter model: A tool for forestry management of young sweet chestnut stands. For. Ecol. Manag. 2022, 514, 120209. [Google Scholar] [CrossRef]
- Nigul, K.; Padari, A.; Kiviste, A.; Noe, S.M.; Korjus, H.; Laarmann, D.; Frelich, L.E.; Jõgiste, K.; Stanturf, J.A.; Paluots, T.; et al. The Possibility of Using the Chapman–Richards and Näslund Functions to Model Height–Diameter Relationships in Hemiboreal Old-Growth Forest in Estonia. Forests 2021, 12, 184. [Google Scholar] [CrossRef]
- Belsley, D.A. Conditioning Diagnostics: Collinearity and Weak Data in Regression; Wiley: New York, NY, USA, 1991; p. 396. [Google Scholar]
- Pinheiro, J.; Bates, D. Mixed-Effects Models in S and S-PLUS; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Sharma, R.P.; Bílek, L.; Vacek, Z.; Vacek, S. Modelling crown width–diameter relationship for Scots pine in the central Europe. Trees 2017, 31, 1875–1889. [Google Scholar] [CrossRef]
- Fu, L.; Duan, G.; Ye, Q.; Meng, X.; Luo, P.; Sharma, R.P.; Sun, H.; Wang, G.; Liu, Q. Prediction of individual tree diameter using a nonlinear mixed-effects modeling approach and airborne LiDAR Data. Remote Sens. 2020, 12, 1066. [Google Scholar] [CrossRef] [Green Version]
- Sainz, R.A.G.; Montero, G. Multilevel linear mixed model for tree diameter increment in stone pine (Pinus pinea) A calibrating approach. Silva. Fennica. 2005, 39, 37–54. [Google Scholar]
- Yang, Y.; Huang, S.; Meng, S.X.; Trincado, G.; VanderSchaaf, C.L. A multilevel individual tree basal area increment model for aspen in boreal mixedwood stands. Can. J. For. Res. 2009, 39, 2203–2214. [Google Scholar] [CrossRef]
- Robinson, G.K. That BLUP is a good thing: The estimation of random effects. Stat. Sci. 1991, 6, 15–32. [Google Scholar]
- Hao, Y.; Widagdo, F.R.A.; Liu, X.; Quan, Y.; Dong, L.; Li, F. Individual tree diameter estimation in small-scale forest inventory using UAV laser scanning. Remote Sens. 2020, 13, 24. [Google Scholar] [CrossRef]
- Liu, X.; Hao, Y.; Widagdo, F.R.A.; Xie, L.; Dong, L.; Li, F. Predicting Height to Crown Base of Larix olgensis in Northeast China Using UAV-LiDAR Data and Nonlinear Mixed Effects Models. Remote Sens. 2021, 13, 1834. [Google Scholar] [CrossRef]
- Wang, Y.; LeMay, V.M.; Baker, T.G. Modelling and prediction of dominant height and site index of Eucalyptus globulus plantations using a nonlinear mixed-effects model approach. Can. J. For. Res. 2007, 37, 1390–1403. [Google Scholar] [CrossRef]
- Kalliovirta, J.; Laasasenaho, J.; Kangas, A. Evaluation of the laser-relascope. For. Ecol. Manag. 2005, 204, 181–194. [Google Scholar] [CrossRef]
- Koenker, R.; Hallock, K.F. Quantile regression. J. Econ. Perspect. 2001, 15, 143–156. [Google Scholar] [CrossRef]
- Li, H.; Zhao, P. Improving the accuracy of tree-level aboveground biomass equations with height classification at a large regional scale. For. Ecol. Manag. 2013, 289, 153–163. [Google Scholar] [CrossRef]
- Dong, L.; Zhang, L.; Li, F. A compatible system of biomass equations for three conifer species in Northeast, China. For. Ecol. Manag. 2014, 329, 306–317. [Google Scholar] [CrossRef]
- Dong, L.; Zhang, L.; Li, F. Additive biomass equations based on different dendrometric variables for two dominant species (Larix gmelini Rupr. and Betula platyphylla Suk.) in natural forests in the Eastern Daxing’an Mountains, Northeast China. Forests 2018, 9, 261. [Google Scholar] [CrossRef] [Green Version]
- Xie, L.; Widagdo, F.R.A.; Dong, L.; Li, F. Modeling height–diameter relationships for mixed-species plantations of Fraxinus mandshurica Rupr. and Larix olgensis Henry in Northeastern China. Forests 2020, 11, 610. [Google Scholar] [CrossRef]
- Bronisz, K.; Mehtätalo, L. Mixed-effects generalized height–diameter model for young silver birch stands on post-agricultural lands. For. Ecol. Manag. 2020, 460, 117901. [Google Scholar] [CrossRef]
- Zheng, J.; Zang, H.; Yin, S.; Sun, N.; Zhu, P.; Han, Y.; Kang, H.; Liu, C.; Greening, U. Modeling height-diameter relationship for artificial monoculture Metasequoia glyptostroboides in sub-tropic coastal megacity Shanghai, China. Urban For. Urban Greenin. 2018, 34, 226–232. [Google Scholar] [CrossRef]
- Lavery, M.R.; Acharya, P.; Sivo, S.A.; Xu, L.J. Number of Predictors and Multicollinearity: What Are Their Effects on Error and Bias in Regression? Commun. Stat.-Simul. Comput. 2017, 48, 27–38. [Google Scholar] [CrossRef]
- Shahzad, M.K.; Hussain, A.; Burkhart, H.E.; Li, F.; Jiang, L. Stem taper functions for Betula platyphylla in the Daxing’an Mountains, northeast China. J. For. Res. 2021, 32, 529–541. [Google Scholar] [CrossRef]
- Zhang, X.; Chhin, S.; Fu, L.; Lu, L.; Duan, A.; Zhang, J. Climate-sensitive tree height–diameter allometry for Chinese fir in southern China. Forestry 2018, 92, 167–176. [Google Scholar] [CrossRef]
- Xu, Q.; Lei, X.; Zang, H.; Zeng, W. Climate Change Effects on Height–Diameter Allometric Relationship Vary with Tree Species and Size for Larch Plantations in Northern and Northeastern China. Forests 2022, 13, 468. [Google Scholar] [CrossRef]
- Zhang, X.; Fu, L.; Sharma, R.P.; He, X.; Zhang, H.; Feng, L.; Zhou, Z. A Nonlinear Mixed-Effects Height-Diameter Model with Interaction Effects of Stand Density and Site Index for Larix olgensis in Northeast China. Forests 2021, 12, 1460. [Google Scholar] [CrossRef]
- Cade, B.S.; Noon, B.R. A gentle introduction to quantile regression for ecologists. Front. Ecol. Environ. 2003, 1, 412–420. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Variables | N | Maximum | Minimum | Mean | Std. |
|---|---|---|---|---|---|---|
| Tree-level | D (cm) | 10,841 | 41.70 | 3.40 | 19.30 | 7.28 |
| H (m) | 30.50 | 3.00 | 17.01 | 6.51 | ||
| BAL (m2·ha−1) | 53.02 | 0.00 | 20.12 | 10.69 | ||
| Rd | 2.21 | 0.30 | 0.98 | 0.20 | ||
| Stand-level | AGE (year) | 183 | 59 | 12 | 45.54 | 13.08 |
| BAS (m2·ha−1) | 53.55 | 9.62 | 33.76 | 6.89 | ||
| Ddom (cm) | 38.65 | 9.33 | 28.20 | 5.78 | ||
| Dq (cm) | 33.57 | 7.21 | 21.98 | 5.96 | ||
| SD (trees·ha−1) | 4450 | 336 | 1163.16 | 841.47 | ||
| Hdom (m) | 29.62 | 5.15 | 21.28 | 5.89 |
| Method | ||||||||
|---|---|---|---|---|---|---|---|---|
| BM | 31.3159 | 0.0592 | 1.6764 | 0.7250 | 1.4811 | |||
| (0.6287) | (0.0025) | (0.0448) | ||||||
| BMM | 21.0797 | 0.0707 | 0.6376 | 1.2268 | 34.2663 | 0.0002 | −0.0168 | |
| (0.4754) | (0.0038) | (0.0265) | ||||||
| BQR(τ) | ||||||||
| τ = 0.1 | 26.0932 | 0.0512 | 1.7087 | |||||
| (0.9622) | (0.0036) | (0.0688) | ||||||
| τ = 0.2 | 25.8663 | 0.0609 | 1.8218 | |||||
| (0.7057) | (0.0032) | (0.0624) | ||||||
| τ = 0.3 | 27.9600 | 0.0569 | 1.6794 | |||||
| (0.9067) | (0.0036) | (0.0612) | ||||||
| τ = 0.4 | 31.1191 | 0.0527 | 1.6053 | |||||
| (1.5717) | (0.0051) | (0.0829) | ||||||
| τ = 0.5 | 36.0700 | 0.0462 | 1.5256 | |||||
| (1.6903) | (0.0039) | (0.0601) | ||||||
| τ = 0.6 | 36.0139 | 0.0519 | 1.6015 | |||||
| (1.2384) | (0.0038) | (0.0657) | ||||||
| τ = 0.7 | 34.9003 | 0.0599 | 1.6791 | |||||
| (0.8392) | (0.0032) | (0.0567) | ||||||
| τ = 0.8 | 33.1376 | 0.0733 | 1.8325 | |||||
| (0.5763) | (0.0034) | (0.0633) | ||||||
| τ = 0.9 | 31.6763 | 0.0899 | 1.9441 | |||||
| (0.4080) | (0.0035) | (0.0650) |
| Method | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| GM | −3.3145 | 0.9844 | 1.7664 | 0.0849 | 0.4786 | 1.6168 | |||
| (0.1912) | (0.0050) | (0.1133) | (0.0043) | (0.0270) | |||||
| GMM | −4.0067 | 1.0012 | 1.9844 | 0.0842 | 0.4585 | 1.2624 | 1.5059 | 0.6118 | −0.8614 |
| (0.4572) | (0.0096) | (0.2325) | (0.0069) | (0.0423) | |||||
| GQR (τ) | |||||||||
| τ = 0.1 | −3.9338 | 0.9595 | 1.5560 | 0.0931 | 0.7510 | ||||
| (0.4083) | (0.0112) | (0.2457) | (0.0082) | (0.0787) | |||||
| τ = 0.2 | −4.0827 | 0.9666 | 1.8831 | 0.0957 | 0.6049 | ||||
| (0.3306) | (0.0073) | (0.1762) | (0.0064) | (0.0524) | |||||
| τ = 0.3 | −4.1662 | 0.9754 | 2.0643 | 0.0979 | 0.5567 | ||||
| (0.2491) | (0.0049) | (0.1495) | (0.0047) | (0.0418) | |||||
| τ = 0.4 | −3.6267 | 0.9712 | 1.9589 | 0.0967 | 0.5314 | ||||
| (0.2105) | (0.0039) | (0.1275) | (0.0043) | (0.0310) | |||||
| τ = 0.5 | −3.2454 | 0.9754 | 1.8773 | 0.0907 | 0.4902 | ||||
| (0.2140) | (0.0057) | (0.1288) | (0.0056) | (0.0338) | |||||
| τ = 0.6 | −3.0998 | 0.9876 | 1.8515 | 0.0815 | 0.4175 | ||||
| (0.1907) | (0.0053) | (0.1130) | (0.0051) | (0.0271) | |||||
| τ = 0.7 | −2.8916 | 0.9965 | 1.7750 | 0.0748 | 0.3622 | ||||
| (0.2052) | (0.0056) | (0.1124) | (0.0051) | (0.0254) | |||||
| τ = 0.8 | −2.7319 | 1.0094 | 1.7349 | 0.0672 | 0.3100 | ||||
| (0.3100) | (0.0082) | (0.1037) | (0.0064) | (0.0244) | |||||
| τ = 0.9 | −2.3053 | 1.0143 | 1.5673 | 0.0691 | 0.3060 | ||||
| (0.2540) | (0.0069) | (0.1593) | (0.0063) | (0.0266) |
| Method | RMSE (m) | AIC | |
|---|---|---|---|
| BM | 0.7176 | 3.4644 | 56,761.79 |
| GM | 0.9619 | 1.2718 | 35,985.07 |
| BMM | 0.9711 | 1.1078 | 34,737.53 |
| GMM | 0.9710 | 1.1104 | 33,948.04 |
| BQR () | 0.7142 | 3.4853 | 59,101.60 |
| GQR () | 0.9615 | 1.2797 | 35,981.73 |
| Method | Type | MAPE (%) | MAE (m) |
|---|---|---|---|
| BM | No calibration | 18.2495 | 2.8405 |
| Calibration | 10.5692 | 1.5804 | |
| BMM | No calibration | 33.8911 | 4.3097 |
| Calibration | 6.0395 | 0.8680 | |
| BQR | No calibration | 17.8708 | 2.8245 |
| Calibration | 9.8634 | 1.4418 | |
| GM | No calibration | 6.9208 | 0.9793 |
| Calibration | 5.7187 | 0.8457 | |
| GMM | No calibration | 6.9652 | 0.9866 |
| Calibration | 5.6198 | 0.8341 | |
| GQR | No calibration | 6.9132 | 0.9706 |
| Calibration | 5.7063 | 0.8428 |
| Item | Size | BM | BMM | BQR | GM | GMM | GQR |
|---|---|---|---|---|---|---|---|
| MAPE (%) | 0% | 18.2495 | 33.8911 | 16.1894 | 6.9208 | 6.9652 | 6.9132 |
| 2% | 13.2995 | 7.5371 | 11.9451 | 7.1239 | 6.4686 | 6.9088 | |
| 4% | 11.9435 | 6.9144 | 11.0512 | 6.5419 | 6.2921 | 6.4722 | |
| 6% | 11.5118 | 6.6577 | 10.6960 | 6.3072 | 6.1657 | 6.2694 | |
| 8% | 11.3029 | 6.5086 | 10.5192 | 6.1746 | 6.0883 | 6.1471 | |
| 10% | 11.1657 | 6.4064 | 10.3982 | 6.0835 | 6.0216 | 6.0643 | |
| 12% | 11.0548 | 6.3304 | 10.2999 | 6.0186 | 5.9748 | 6.0049 | |
| 14% | 10.9794 | 6.2812 | 10.2327 | 5.9776 | 5.9361 | 5.9675 | |
| 16% | 10.9296 | 6.2382 | 10.1874 | 5.9413 | 5.9055 | 5.9318 | |
| 18% | 10.8887 | 6.2067 | 10.1497 | 5.9161 | 5.8801 | 5.9076 | |
| 20% | 10.8540 | 6.1801 | 10.1172 | 5.8947 | 5.8590 | 5.8861 | |
| MAE (m) | 0% | 2.8405 | 4.3097 | 2.5168 | 0.9793 | 0.9866 | 0.9706 |
| 2% | 2.0494 | 1.0976 | 1.7873 | 1.0848 | 0.9361 | 1.0352 | |
| 4% | 1.8164 | 1.0002 | 1.6410 | 0.9856 | 0.9175 | 0.9649 | |
| 6% | 1.7433 | 0.9612 | 1.5832 | 0.9468 | 0.9042 | 0.9328 | |
| 8% | 1.7066 | 0.9380 | 1.5535 | 0.9243 | 0.8951 | 0.9135 | |
| 10% | 1.6836 | 0.9225 | 1.5334 | 0.9091 | 0.8877 | 0.9006 | |
| 12% | 1.6645 | 0.9111 | 1.5170 | 0.8983 | 0.8821 | 0.8915 | |
| 14% | 1.6514 | 0.9034 | 1.5052 | 0.8911 | 0.8772 | 0.8852 | |
| 16% | 1.6428 | 0.8968 | 1.4976 | 0.8847 | 0.8733 | 0.8794 | |
| 18% | 1.6362 | 0.8921 | 1.4912 | 0.8804 | 0.8701 | 0.8755 | |
| 20% | 1.6304 | 0.8882 | 1.4858 | 0.8766 | 0.8674 | 0.8720 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, F.; Xie, L.; Hao, Y.; Miao, Z.; Dong, L. Comparison of Modeling Approaches for the Height–diameter Relationship: An Example with Planted Mongolian Pine (Pinus sylvestris var. mongolica) Trees in Northeast China. Forests 2022, 13, 1168. https://doi.org/10.3390/f13081168
Lin F, Xie L, Hao Y, Miao Z, Dong L. Comparison of Modeling Approaches for the Height–diameter Relationship: An Example with Planted Mongolian Pine (Pinus sylvestris var. mongolica) Trees in Northeast China. Forests. 2022; 13(8):1168. https://doi.org/10.3390/f13081168
Chicago/Turabian StyleLin, Fucheng, Longfei Xie, Yuanshuo Hao, Zheng Miao, and Lihu Dong. 2022. "Comparison of Modeling Approaches for the Height–diameter Relationship: An Example with Planted Mongolian Pine (Pinus sylvestris var. mongolica) Trees in Northeast China" Forests 13, no. 8: 1168. https://doi.org/10.3390/f13081168